Best model for 1.5, SDXL 1.0 Base, Pony -
1)Taggui https://github.com/jhc13/taggui
wd-vit-large-tagger-v3 https://huggingface.co/spaces/SmilingWolf/wd-tagger
Best model for FLUX dev, FLUX schnell -
1)Joytag Caption - Batch https://github.com/MNeMoNiCuZ/joy-caption-batch https://civitai.com/articles/6723/tutorial-tool-caption-files-for-flux-training-sfw-nsfw
2)Taggui https://github.com/jhc13/taggui
A good model for FLUX dev, FLUX schnell - Florence-2-base-PromptGen Florence-2-base-PromptGen
Instruction for Tags:
1)Taggui
1.Download Taggui
2.Unpack archive and run taggui.exe
3.Select - wd-vit-large-tagger-v3

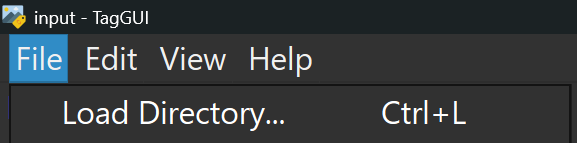
4.FIle > Load Directory (Ctrl+L) - Select folder with images5.Start Auto-Captioning
Settings and Tips:
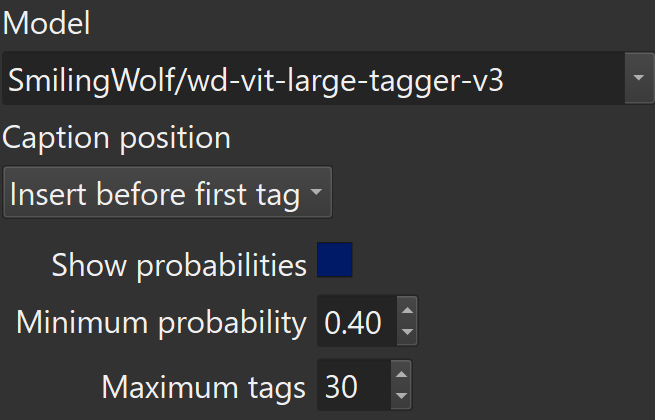
1.Maximum tags - 30 (default) is a good starting point. The more detailed images you select the more tags the model can generate. A lot of tags can create artifacts on generation.
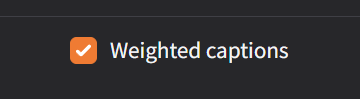
2.Show probabilities - activate weight on tags. Can create more precise tags for image. To activate this futures for training (Kohya_SS) need to activate - Parameters > Advanced > Weighted captions ON.
Instruction for Captions:
1)Joytag Caption
Prepare: Install Python 3.10 and CUDA Toolkit 12.6 if you don't have to. (Installing running requirements)
1.Joytag Caption
2.Download Joytag Caption
3.Unpack archive and run venv_create.bat
3.1.Select a Python version by number: 1 (Python 3.10)
3.2.Enter the name for your virtual environment: Enter
3.3.Do you want to upgrade pip now?: Y
3.4.Do you want to install 'uv' package?: Y
3.5.Do you wish to run 'uv pip install -r requirements.txt'?: Y
4.Install:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124Usage and Tips:
Prepare: Put images inside - input folder in joy-caption-batch-main.
1.Run Terminal inside joy-caption-batch-main folder
2.Run:
python -m venv venv.\venv\Scripts\activatepy batch.pyNote:
Default caption length is 256 which cannot be recommended for character.
Style train - up 300 words.
Character train - up 25 words.
2)Taggui
1.Download Taggui
2.Unpack archive and run taggui.exe
3.Select - Florence-2-base-PromptGen

4. FIle > Load Directory (Ctrl+L) - Select folder with images
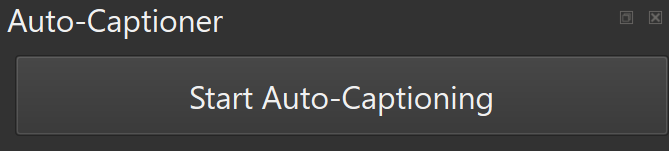
5.Start Auto-Captioning
Settings and Tips:
1.Maximum tokens - 50 (default) is good start point. The recommended maximum value is 300.
2.Number of beams - 10 (default) is a good standard. Increasing this number increase the precision prediction of the detect algorithm. More value requires more VRAM